JILT 1997 (2) - AustLII Paper 5
5. New Legal Services via the Web - AustLII's Research on Legal Inferencing
Legal inferencing technology has advanced considerably over the last two decades. However, such systems have generally taken the form of in-house compliance or document generation systems in large corporations or government agencies. The development of the World Wide Web has created new opportunities both in terms of increasing the accessibility of such systems to the public as well as enabling the development and maintenance costs to be spread widely over multiple knowledge engineers. Further, large repositories of legal information such as AustLII, SCALE Plus and Butterworths Online represent a greater wealth of digital supporting materials, with better currency, than has previously been available to be integrated with inferencing systems.
Legal inferencing systems can be used to develop and deliver a wide range of innovative legal services over the World Wide Web. These will include services customised to the circumstances of the particular inquirer (or client), such as (i) advice on availability of government benefits, (ii) advice on requirements for licences, (iii) interactive 'interviews' to complete legally-oriented application forms; and (iv) interactive generation of customised legal documents. All of these services will depend on complex automated inferences being drawn from large underlying bodies of constantly changing law. This paper [33] outlines how such new legal services are being developed in the AustLII context.
5.1 AustLII's Inferencing Research
As part of AustLII's role as a research centre in computerisation of law, we are conducting a three year research project [34] into the development of legal inferencing systems which use the Internet, and into how their integration into large scale legal information systems like AustLII can result in the development of new legal services via the Internet.
This research project builds on two principal sources, the 'DataLex' research (1985-94), and the development of AustLII (1995-97). The 'DataLex' research project ( Greenleaf et al; 1995b ) on the computerisation of legal information was done mainly in relation to 'stand-alone' collections of legal information, and was unrelated to the web. That research led to two principal conclusions.
First, the most useful decision support systems based on inferencing also incorporate hypertext and text retrieval techniques to allow the user to investigate questions posed by the inferencing system. We are now able to use AustLII as the foundation on which to build legal inferencing systems as part of large-scale decision-support systems. AustLII - its data, indexes, software and usage - provides the necessary infrastructure for this research.
Second, "quasi-natural language" (English like) rulebases have advantages over more traditional symbolic rulebases. The advantages of quasi-natural language inferencing engines are accentuated where the knowledge engineer is any lawyer with a web site. The simple and intuitive syntax of such inferencing engines becomes critical in this context.
5.2 Project goals
The project goals address the key issues in implementing effective legal inferencing over the web, common to both rule-based and case-based legal inferencing, including:
(1) An efficient method of inferencing using remote rulebases This involves a choice between having the processing of inferences conducted by the user's machine, or having a third party server process the inferencing session. At present we have approached the issue by allowing users to invoke the AustLII wysh server which then retrieves the relevant remote knowledgebase(s) and handles the inferencing session. Alternatives which may be explored during the course of the research are implementing the inference engine in a cross platform language such as Java or porting it to various platforms to be invoked as a browser plug-in. Both of these latter two solutions require significantly more development work than our current solution.
(2) An efficient solution to the problem of stateless inferencing Having adopted the inferencing server approach the problem arises of how the necessity for an inferencing system to retain both user-provided and inferred 'facts' in working memory can be best reconciled with the essentially 'stateless' nature of the HyperText Transmission Protocol (HTTP)? An HTTP server does not in itself maintain state (ie retain knowledge of past user behaviour) between user requests, so as to link them to the same user. A variety of techniques may be used to solve this problem including embedding session identifiers in CGI form-based requests, 'magic cookies', ports tied to one host, and (common but unreliable) heuristic assumptions about repeated requests from the one host. However any solution must be efficient in processing and memory terms at both the server and client ends. We discuss our current solution below.
(3) Permitting interaction between distributed knowledgebases The more challenging issue ('cooperative' inferencing) is how to enable different knowledge-base developers to develop knowledge-bases on their own web sites (all remote from the site of the inferencing software), which interact with others' knowledgebases when invoked by users. Again, there are essentially two potential solutions: (a) multiple inferencing sessions may be conducted to deal with different parts of the problem (the cooperating agent model); or a single session could be conducted using knowledge from a variety of distributed knowledgebases. While inferences are being handled by a single server, or if inferencing is conducted by the user agent, the most appropriate approach is probably to conduct a single inferencing session. This allows more finely tuned control on the sharing and hiding of knowledge between different parts of the knowledgebase. However, the distributed inferencing agent model may be more appropriate if knowledgebases or knowledge "webs" become too large to be efficiently dealt with by a single inferencing server or user agent.
(4) Facilitating cooperative knowledgebase development Once knowledgebases can interact other issues are raised. How can an underlying 'ontology' for legal inferencing, and use of a common interface, be best developed so that knowledge representations developed independently by different developers, and located on different servers, can interact to draw legal inferences?(Gruber Year) What tools can be developed to assist developers in ascertaining what knowledge already exists on remote sites? What standards, methodologies and associated tools can be developed to ensure that knowledgebases are as reuseable, and generic as possible? Should developers specify what knowledgebases may be invoked to solve sub-problems or should inferencing servers or user agents provide facilities so that users can search for relevant knowledgebases during the course of an inferencing session?
Other issues made more significant by web-based inferencing include the possibility of sharing or reusing ontologies from other disciplines as well as more generalised common sense ontologies. Use of other types of knowledge, and permitting legal knowledgebases to be used by non-legal inferencing systems, raises the issue of whether knowledge should be stored in a more open form such as the knowledge interchange format (KIF). As well, or alternatively in relation to some problems, specialist intelligent agents may be used in relation to non-legal sub-problems. In this case inter-agent communication standards such as the knowledge query and manipulation language (KQML) need to be considered.
(5) Integrating inferencing in the web. How can the interface and process of legal inferencing be best integrated, on the World Wide Web, with the hypertext and text retrieval presentation of the underlying legal texts, particularly when these are very large-scale, not project-specific, distributed, and constantly changing? The initial issue for us was how well our prior 'DataLex' research on integration ( Greenleaf et al; 1995b ) could be extended to accommodate the additional demands of the 'unlimited' web context. This has been accomplished partly by means of real time mark-up of knowledgebases to include links to relevant supporting legal materials and also by allowing embedded searches.
(6) Effective use of user feedback. Can usage patterns of legal inferencing systems on the web (including the hypertext / retrieval interactions) be captured in meaningful ways and used in the aggregate as feedback to refine such systems? Effective use of usage patterns raises difficult issues of interpreting the data, as well as privacy considerations, but is such a valuable and available resource in web-based services that it cannot be ignored. AustLII voluntarily adheres to the privacy principles set out in the Privacy Act 1988 (Cth). Any monitoring of user behaviour will be developed in accordance with privacy principles.
(7) Attempt to resolve the tension between 'readability' and expressive power. The 'DataLex' research ( Greenleaf et al; 1995b, part 4.2 ) argues for the necessity for 'English-like' knowledge representations in legal inferencing, but this demand poses problems in properly utilising predicate logic. The work by Johnson and Mead SoftLaw Corporation is of relevance to, but does not resolve, this problem. This issue is not particular to web-based inferencing, but cannot be avoided in resolving other problems. More particular to the web context is the problem of making the knowledgebases as reusable for legal and non-legal inferencing as possible. This involves use of a standard knowledge representation format. However, to use such a standard (e.g. KIF) as the primary knowledge representation language may make knowledgebases far less accessible to maintainers and developers, and transparent to users. Accordingly, knowledge sharing may require conversion utilities.
(8) Tools to assist in 'scaling up' Which elements (if any) of the development of legal knowledge representations (particularly legislation-based ones) are capable of complete or partial automation, so as to assist with the problems of scaling-up legal inferencing? Can both the web availability of representations of the underlying texts on a large scale, and the hypertext and text retrieval relationships captured in those texts, be used to assist large-scale scaling-up?
This is probably the most challenging and intractable issue. Anything approaching complete automated conversion of legislation into knowledge-bases is unattainable (at least in this project), as it would involve solving many of the major problems of automated processing of natural language. Our goals are limited to attempting to find whether there is any extent to which legislation may be automatically 'pre-processed' so that the task of the human expert who must convert it into a knowledge-base is reduced - particularly where large-scale knowledge-bases are planned. In other words, it is an attempt to produce a 'useful first cut' of a knowledge-base, not the finished product. Reasons for optimism in relation to this limited goal are (i) the 'quasi-natural language' knowledge representation we use is, in effect, a formal paraphrasing of legislation; and (ii) our previous experience in automated heuristic processing of legislation with hypertext mark-up tools.
5.3 Research on Legal Inferencing Over the Web
There is as yet little published work or examples in the field of legal rule-based inferencing over the net. For more details of related research see Greenleaf et al (1997b) The principal web resource on legal inferencing, Kellow; 1997 ) ( Johnson and Dayal; 1997 )
In domains other than law, there appears to be considerable relevant work. Neches and Gruber; 1994 ) Other parts of this effort which are likely to be relevant to our research include the Knowledge Query and Manipulation Language (KQML) ( Finin and Fritzson; 1994 ) and the Knowledge Interchange Format (KIF),( Genesereth and Fikes; 1992 ) both of which are likely to be relevant to enable the inferencing system to interact with other information systems or intelligent agents over the Internet or other networks. Also valuable are ontologies available over the web from Stanford KSL ( Rice et al; 1995 ) and Cycorp's Cyc ontology .
5.4 AustLII's WYSH system
AustLII's web inferencing project has been underway for less than a year, but significant progress has been made in relation to issues (1)-(5) as indicated above, and background work undertaken in relation to (7) and (8). Issue (6) remains untouched as yet.
5.4.1 The YSH inference engine
The YSH inference engine written by Mowbray (1991-1994) (See Greenleaf G et al (1995b) for a description of its features) which formed part of the DataLex WorkStation software is the basis of AustLII's web inference engine. In summary, YSH implements rule-based inferencing, with rules being both forward and backward chaining by default, but able to be declared to be FORWARD, BACKWARD, DAEMON or other rule types. The '(quasi) natural language' knowledge representation is close to a paraphrase of ordinary English (at least as used in statutes!), with keywords such as ONLY IF, EQUALS etc. Dynamic information is stored as facts with Boolean (yes/no/unknown) values or non-Boolean (numbers, amounts, dates or genders). Named subjects declared to be a PERSON, THING, or PERSONTHING will be instantiated and correct pronouns used in dialogues. All inferencing dialogues are generated 'on the fly' from the knowledgebase. YSH also provides limited forms of automated document generation and case-based reasoning, both of which are integrated with the rule-based component.( Greenleaf et al; 1994 )
5.4.2 The wysh web interface to YSH
All aspects of YSH's inferencing now work over the web, via the wysh (for 'web-ysh') user interface to YSH, [35] a Common Gateway Interface (CGI) application. Knowledgebases developed for YSH can be placed on a web page and they will then run without alteration through the wysh interface (examples are given below). The inferencing server approach was adopted because it allows access from a wide range of browsers (unlike a Java based solution), is not limited by the processing capacity of the user agent hardware and, initially, allowed more rapid development of a working system based on the YSH inferencing engine.
Wysh is able to read knowledgebases out of HTML pages, irrespective of the web server on which those knowledgebases are located. The only HTML tags which are needed are the <!--ysh> and <!--/ysh-->, to indicate where on a web page a ysh knowledgebase begins and ends. The YSH and the wysh interface are now available to anyone who wishes to use them over the web to develop applications. There are two ways for knowledgebase developers to use wysh .
Anyone who wishes to publish a YSH knowledge base on their web page can do so by adding a link which passes the location of the knowledgebase and various other optional parameters to the wysh CGI script. For example, the following HTML enables the intellectual property knowledgebase, located on a web page on a different AustLII server to be run using wysh :.
<A HREF="http://www.austlii.edu.au/do/wysh?
rulebase=http://www2.austlii.edu.au/~graham/wysh/ipwstn.html&markup=ON">Run consultations </A> using the IP Knowledgebase (1991- 94)
Selecting this link results in a consultation starting, as described below. Links such as this may be located on the page on which the knowledgebase is located, or on any other page. For example, the link which invokes a knowledgebase for s15 of an Act could be located as a 'Consult' button on the web page for the text of that section.
The second way in which wysh can be used is via the 'wysh manual start page' shown below. It is designed for small rulebases to be tested and amended, and includes mechanisms by which the consistency of knowledgebases, and automatically inserted hypertext links, can be checked.
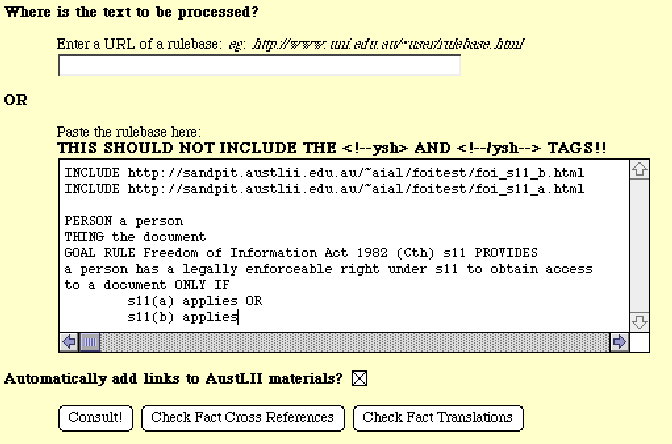
Figure: The wysh 'manual start' page, with a small rulebase to be tested
5.4.3 The 'wysh index' - Sample Knowledgebases, Other Aids
Demonstration wysh knowledgebases, and tools to assist knowledgebase development can be accessed from the ' wysh index '.
Example knowledgebases include those concerning Australian privacy law [36] and intellectual property law, [37] reflecting work done for the previous DataLex WorkStations ( Greenleaf et al; 1995b ). There are also some small examples used for teaching purposes.
5.4.4 The User Interface to wysh applications
Once the consultation is started, the user is presented with a choice of goals, and a dialogue commences. The example below is from our intellectual property knowledgebase.
The following goals are defined:
1) Copyright Act 1968 - s29 (Publication)
2) Copyright Act 1968 - s31 (Exclusive Rights)
3) Copyright Act 1968 - s32 (Subsistence)
4) Copyright Act 1968 - s33 (Duration)
Please select a goal ?
Having selected a goal, the user then engages in a dialogue, mainly through variants of the screen below. 'Facts' displays user-supplied facts (which may be retracted one at a time using 'Forget' or 'Forget n'). 'Conclusions' displays interim conclusions (with explanations elicited using the command 'How n'). 'Why?' explains the current question. All dialogues are generated from the knowledgebase with the types of hypertext links shown below.

Figure: wysh interface showing interim conclusions and current question
5.4.5 An approach to the 'state' problem
A number of different approaches were considered as solutions to the problem of statelessness on the web. Broadly, as noted earlier, two approaches to the underlying architecture can be adopted. One approach is to rewrite the inferencing engine for the user's machine as either a Java applet or as a browser plug-in. The second approach implements a client-server model, maintaining the inferencing engine at the server end and providing a simple forms based interface for the client.
At this stage of the project, the latter approach has been adopted. This avoided both a major rewrite of the inferencing engine and the many problems still remaining with cross-platform code. In keeping with AustLII's general philosophy, we also favoured an approach which was consistent with the cross-platform and user-interface concerns of the World Wide Web.
The decision to remain with a client-server approach led us to an analysis of two different approaches at the server end. An early solution created a dedicated HTTP server for each remote session. Although simple to implement, this approach had major overheads and was abandoned in favour of an approach which maintained as much functionality in the standard HTTP server as possible. Our current implementation uses a simple CGI interface to connect to one of a number of stateful YSH sessions which run via internal UNIX domain sockets.
This approach allows for each session to maintain state and interact in a fast and secure manner with the CGI script which handles the bulk of the user-interface. The advantages of this approach include the ability of our interface to be used on any HTML 2.0 or later browser (graphical or text-based). We are able to update our expert system shell as required and there are a minimal number of complex cross-platform issues to deal with. Authentication between individual transactions in a 'session' is handled with a combination of a 'session id' and host-based authentication. Cookies would also provide an appropriate method of authentication.
It is envisaged that the issue of architecture will be readdressed in the near future, with more thought being given to the possibility of a Java based solution.
5.4.6 Cooperative inferencing using wysh
'Cooperative inferencing' allows wysh knowledgebase developers to declare in their rulebases that other rulebases on web pages located anywhere on the web are to be 'included' in consultations running using their rulebase.
Other knowledgebases are 'read in' to a wysh knowledgebase by use of the INCLUDE keyword and the URL of the knowledgebase to be included. For example, in this small knowledgebase, two other knowledgebases are read in.
INCLUDE http://sandpit.austlii.edu.au/~aial/ foitest/foi_s11_b.html
INCLUDE http://sandpit.austlii.edu.au/~aial/ foitest/foi_s11_a.html
PERSON a person
THING the document
GOAL RULE Freedom of Information Act 1982 (Cth) s11 PROVIDES
a person has a legally enforceable right under s11 to obtain access to a document ONLY IF
s11(a) applies OR
s11(b) applies ( online wysh example - FOI s11 )
The INCLUDE function will also read any knowledgebases which are INCLUDEd in any of the knowledgebases it finds. Multiple knowledgebases may therefore be 'chained' together by hypertext links, without any one knowledgebase listing all of the 'cooperating' knowledgebases. However, wysh will not reload the same knowledgebase twice, thereby avoiding infinite loops.
At present, all INCLUDEd knowledgebases are read before an inferencing session commences. This is effective while the number and size of chained knowledgebases remains manageable. Other more efficient mechanisms of deciding when to read which knowledgebases (or parts thereof) are under consideration.
5.4.7 Tools to assist in the development of cooperative knowledgebases
The potential advantages of cooperative inferencing are considerable, as it takes advantage of the web's inherent facilitation of a number of parties contributing small components of an overall solution to a problem. However, a directly or indirectly INCLUDEd knowledgebase may be changed or added to without the knowledge of others who INCLUDE it, a problem typical of hypertext on the web, but with more significant consequences for knowledgebases. These factors give a new importance to a number of issues, including problems of transparency, the need for conflict resolution rules, and the value of shared ontologies, which we have not yet explored fully. They also indicate a need for specialised tools which, among other things, index and allow searching over rules. Such tools may be developed during the course of the research.
To enable users to see the content of other knowledgebases that are being included, it is useful to make the URLs that follow each INCLUDE into live hypertext links to those knowledgebases.
At present the most useful tool for knowledgebase developers is the 'Check Fact Cross References' button on the wysh manual start page. This indicates which rules contain references to particular facts. Therefore, developers can ensure that the facts which they expect to invoke rules contained in another knowledgebase will in fact invoke those rules.
5.4.8 Integrating inferencing into the web
Knowledgebases and inferencing sessions need to be linked to the legal sources on which they are based. ( Greenleaf G et al; 1995b ) This is achieved in a number of ways with wysh : by automated hypertext links to AustLII legislation; by explicit hypertext links from rulebases; and by pre-stored searches linked to rulebases. Automated hypertext links from rulebases
When a wysh inferencing session is invoked from a hypertext link from a web page, the inclusion of '&markup=ON' after the URL of the target knowledgebase will result in the knowledgebase being 'marked up' by AustLII's automated mark-up scripts, so that all dialogues, explanations and reports will be presented to users with hypertext links out to any legislative references.
The mark-up software uses heuristics to create links to names of Acts, to specific sections of Acts, and to cases identified by certain case citations (e.g. 'CLR' references to the Commonwealth Law Reports), provided the materials are contained on AustLII. One full reference to a piece of legislation (including a year) in the knowledgebase is normally required, but the heuristics then attempt to determine which subsequent (or prior) section references are to that Act. If a default jurisdiction is specified (an option), the software will attempt to process links for that jurisdiction first, and will resolve any ambiguities in legislation names in favour of that jurisdiction. The automated linking works with a high degree of accuracy over AustLII's more than 400,000 sections of legislation.
For example, in the small knowledgebase above, the references to 's11(a)' and 's11(b)' result in automatic correct links to s11 of the Freedom of Information Act 1982 on AustLII. These links appear in questions, reports and explanations. If the user follows a hypertext link to the text of s11, and then selects the '[Noteup]' button at the head of that section, it will cause a pre-stored search of the whole AustLII database, for all cases and other legislation referring to that section (26 cases, one other section and one tax ruling, at the time of writing). In this way, wysh users can be led seamlessly from inferencing to hypertext to text retrieval.
Since the linking process is dynamic, being re-run every time a consultation is commenced, new links may be created if new material (for example, another jurisdiction's legislation) is added to AustLII after the knowledgebase was created.
This automated hypertext linking of knowledgebases to sources is therefore capable of speeding up the development process as well as assisting users to determine the currency of a rulebase (discussed further below). Explicit hypertext links
The LINK ... TO keywords allow for additional hypertext links to be explicitly defined in a knowledgebase. In the above example, the knowledgebase for s11(b) contains an explicit link to the statutory definition of ' document of an agency ':
The link could be to any document anywhere on the web. Pre-stored searches
In the above example, the knowledgebase for s11(b) contains a different form of explicit link, a search over AustLII for any document referring to an ' official document of a Minister ' (with display by relevance ranking using 'freeform' searching):
LINK official document of a Minister TO http://search.austlii.edu.au/do/sinosrch.pl?query=official+document+of+a+Minister&searchscope=Title+%26+Text&selection=All+AustLII+Databases&numhits=200&searchtype=Freeform
By the same means, searches over non-AustLII resources (e.g. Alta Vista) may be embedded. An answer to 'knowledgebase - lag'
A crucial 'real world' problem of legal inferencing systems is that the development of knowledgebases (like other value-added secondary sources such as legal textbooks) must necessarily lag somewhat behind the case law and legislation that they embody, yet users in legal practice value and require resources that reflect the law as it is 'up to the minute'.
An important aspect of the three forms of links from knowledgebases to textual sources described above is that they start to provide one of the few ways to do anything practical about this problem. If the inferencing dialogue can also direct users to more recent textual sources to assist in the checking of its generated conclusions, then the use of knowledgebases in legal practice is more likely. Links to a constantly updated set of textual sources such as AustLII are likely to reveal sources more recent than the knowledgebase. The embedding of search expertise in key terms, and the ability to '[Noteup]' links to legislation by stored searches, are useful bridges to a dynamic text collection.
The next step is to utilise features more specific to a particular consultation in constructing automated 'updating' searches. One possibility is to take the principal conclusions generated by an inferencing session and automatically transform that text into a 'freeform (relevance ranking' search of AustLII, possibly limited to texts dated after the last update of the knowledgebase. In a related fashion, ( Daniels and Rissland ; 1997 ) one can use the output of a CBR system to construct document queries. Advantages of knowledgbases as web pages
Finally, there are a number of advantages in the original wysh knowledgebase (not just a copy of it) being published on a web page, or pages. The transparency of the knowledgebase is enhanced by the 'visibility' of the original.(Greenleaf G et al; 1995b) The knowledgebase can have the same hypertext mark-up as other texts (links to statutory provisions, defined terms etc.), and as will be used in the inferencing dialogues.
The knowledgebase is searchable at the same time as cases and statutes are being searched, so users can 'find' not only texts that are relevant to their search requests, but consultations as well. One advantage of using a 'quasi-natural language' knowledge representation is that it is possible to search for parts of a knowledgebase using the same search queries as a search over the source texts. The ability to break a knowledgebase into separate pages (a by-product of cooperative inferencing) also improves the effectiveness of searches, as the document unit searched (e.g. a knowledgebase for one section of an Act) can be isomorphic with the document units of the source texts.
5.5 Current and future work
The first stage of AustLII's inferencing research has resulted in the full migration of the DataLex approach to legal inferencing to the World Wide Web. YSH knowledge-bases now run over the web through the wysh interface. All of the forms of integration between inferencing, hypertext, and text retrieval explored there are now operative on AustLII.
However, this work extends the DataLex approach in significant ways. The wysh interface provides one solution to the problem of maintaining state in web interactions, while not requiring anything more than the standard HTML and CGI facilities of the web. Our initial approach to remote and cooperative inferencing provides a means for wysh knowledgebases to interact with other wysh knowledgebases located anywhere on the web. We have developed a variety of automated and customised means of linking knowledgebases and inferencing dialogues to a large dynamic 'real world' legal information system.
Over the next two years the project is likely to advance in two main directions: (i) all of the initial components will be developed further, either by refinement or replacement and (ii) the issues of scaling up will then become central, and will be tested by developing a number of large-scale applications in the context of the AustLII databases.
5.5.1 A new inferencing engine
An inferencing engine which handles predicate logic, but which retains the quasi-English and declarative nature of YSH rules is currently being developed. The new engine will allow new operators including "A" and "ALL". It will also allow inheritance between objects for the purposes of type checking. Accordingly, an object "author" may be defined such that it is a subtype of "person". Accordingly, any rule that deals with "person"s will also be able to answer a relevant query from another rule in relation to "author"s. Further, any range checking that applies to a parent such as "a person's birthday" will automatically apply to any object which is a subtype of that object such as "a child's birthday".
Lastly, it is intended that operators will be added to allow scoping, and precedence to be specified. Accordingly, phrases such as "for the purposes of this section" and "subject to section 13" will be able to be appropriately interpreted by the inference engine. There is some question as to whether adding such operators will lower the rigour demanded of knowledge base developers by not requiring them to construe the semantic structure of a statute and thereby allow errors and inconsistencies to appear in the rulebase more easily.
5.5.2 Scaling-up knowledgebase development
Background work is also underway in the partial natural language processing of legislative texts. It is anticipated that the initial approach will involve drawing from legislative texts a series of complete clauses connected, where possible, by conjunctions (and/or/etc.) or subordinating conjunctions (if/provided/etc.). This will require identifying such structural words (conjunctions and subordinate conjunctions) in the text. This will quite probably involve some user input in determining which of the potentially structural words are and should be treated as structural words.
31(1) For the purposes of this Act , unless the contrary intention appears,
copyright , in relation to a work , is the exclusive right:
(a) in the case of a literary, dramatic or musical work , to do all or any
of the following acts:
(i) to reproduce the work in a material form ;
(ii) to publish the work ;
(iii) to perform the work in public;
(iv) to broadcast the work ;
(v) to cause the work to be transmitted to subscribers to a
diffusion service;
(vi) to make an adaptation of the work ;
(vii) to do, in relation to a work that is an adaptation of the
first-mentioned work , any of the acts specified in relation to
the first-mentioned work in subparagraphs (i) to (v),
inclusive; and ...
For example in converting s31(1) of the Copyright Act (extracted below) into a rule, ideally the sentence would not be repeated for each type of work. Therefore, in the phrase "literary, dramatic or musical work" the user would indicate that the comma and the word "or" should not be treated as structural. However each of the rights would ideally be dealt with in a separate rule, particularly if there are further definitions or case law which relate to each. Therefore, the semicolons and the "and" between the paragraphs should be treated as structural.
Having gone through the process of identifying structural words, a number of other difficult problems are faced.
The first problem is ellipsis. As indicated, ideally a separate rule would be associated with each right. In the above example, all but the first right omit the beginning portion of the sentence. This is because that beginning portion is assumed to apply in relation to each right. In order to produce a series of simple clauses, the beginning of the sentence needs to be inserted before each of the rights giving:
copyright, in relation to a work, is the exclusive right to reproduce the work in a material form and
copyright, in relation to a work, is the exclusive right to publish the work and ...
Ellipsis of this kind is extremely common in statutory texts. While it can generally be dealt with easily, it may require human input to determine exactly what portion of the initial clause is missing from subsequent clauses (or what portion of the last clause is missing from earlier clauses). While heuristics may be able to be used by software to make judgements about this, human input would probably be better at this early stage than after processing, when it will involve looking for wrong interpretations in the text.
Another problem is anaphora. In the existing inference engine (and also in the engine currently being developed) references to named subjects or objects must be explicit. However, in English texts, references to a noun are often by way of a pronoun, known in this context as an anaphor. For example in the phrase below, the word "He" is an anaphor which refers to my dog.
My dog has fleas. He needs a flea collar.
Often such references can be difficult to resolve, particularly without semantic understanding of the sentence. Where the pronoun is within the same clause, it may not be necessary to resolve it since any question produced by the inference engine which is based on that clause should be meaningful to the ultimate user regardless of whether the anaphor has been replaced by the relevant noun. However, where a pronoun is used to refer to a noun in a previous or later clause, the reference will need to be resolved. Fortunately, this form of anaphora is not traditionally common in legislative texts because of its tendency to introduce ambiguity. Further, this resolution can be assisted by heuristics, although ultimately a human will need to decide what the reference is to.
Once a first cut, consisting of simple clauses connected where appropriate by conjunctions, has been produced, the developer will need to ensure that corresponding clauses have identical wording in order to guarantee that backward and forward chaining proceeds correctly. Tools may also be developed to assist with this process by identifying possible matching clauses. Other clauses will need to be completely reworded to be turned into an appropriate rule.
5.5.3 Embedding inferencing in AustLII's databases
Once we are in a position to produce some reasonably large legal knowledge-bases, the question arises of how can these best be made accessible to users. The availability of the very large scale legal source materials such as are found on AustLII presents valuable opportunities to embed knowledge-based systems in the context of such materials - an opportunity not previously available. This is the complement of the question of how to make source materials available from inferencing sessions, which was discussed above.
The DataLex research suggested two primary approaches which are also relevant in the web context:
(1) Adding 'Infer' buttons to pages of legislation where there is an associated knowledgebase so that users can commence an inference session in the course of browsing through a section. This may be useful not only in allowing conclusions to be drawn in relation to a specific fact situation but also in allowing a user to be understand the structure and interaction of the section they are looking at and related sections.
(2) Allowing returning knowledgebases as results in searches. This may give users a more useful version of the relevant legislative provisions, depending of course on their aim and expertise in the area.
Both techniques should be valuable in encouraging users to try using inferencing software. This has been one of the major barriers in integrating inferencing systems in government agencies and other work places. Familiarity with the inferencing process among Internet users may increase the popularity, and hopefully therefore the resources available for the development of, knowledgebases and inferencing tools generally.
5.6 Conclusion - New legal services via the web
The web creates new opportunities for delivering computerised legal services to lawyers and the public. The wysh project seeks to take maximum advantage of these opportunities in a manner which is capable of developing a momentum beyond the wysh project itself.
The key aspects to achieving this momentum from a user perspective are:
(1) A non-platform or browser specific system for conducting inference sessions using remote knowledgebases.
(2) A simple self explanatory user interface.
(3) Hypertext links to up-to-date supporting materials to enable users to investigate questions both to determine an appropriate answers and to ensure that the knowledgebase is up-to-date.
(4) Transparent rulebases so that users can satisfy themselves, where unsure, that the rulebase is in fact a correct interpretation of the relevant law.
(5) Ready access from a high usage legal database (AustLII), both from searches and from sections or other nodes within the database.
The key aspects to achieving momentum from a developer perspective are:
(1) Simple invocation of the inference engine.
(2) Simple integration with existing knowledgebases, making any individual developer's task comparatively small.
(3) Simple syntax so that non-programmers can develop knowledgebases.
(4) Tools to assist in developing and maintaining knowledgebases.
The ultimate goal, a web of legal knowledge maintained and extended by distributed unrelated legal knowledge engineers, should be of great benefit to both lawyers and the public.
Last revised: Wed 23 Feb 2005
BAILII: Copyright Policy | Disclaimers | Privacy Policy | Feedback | Donate to BAILII
URL: https://www.bailii.org/uk/other/journals/JILT/1997/austlii5_2.html