Reasonable Design
Gordon Hughes
Safety Systems Research Centre
Computer Science Department
University of Bristol
[email protected]
Abstract
In general, the acceptability of a system can be judged directly from an estimation of its reliability or indirectly in terms of its compliance with current best practice for design and manufacture as defined by standards and codes of practice. A demonstration that all reasonable steps have been taken to ensure reliability and fitness for purpose of a system would appear to be the system designer's/supplier's best defence in the event of system failure. Computer-based systems and communication networks pose particular difficulties for reliability estimation and the rate of technological change means that current standards are of limited value.
This paper reviews the difficulties involved in the design and justification of complex digital systems and attempts to provide a basis for demonstrating 'reasonable' (or unreasonable) design in a probabilistic way as associated with ALARP criteria. At present there are significant residual uncertainties in the processes involved and it is concluded that it would be sensible for engineers and scientists to work with the legal profession to develop a set of decision support tools which could facilitate a just legal framework.
Keywords: Computers, communications, networks, software, design faults, ALARP, reliability, justification, decision support.
This is a Refereed Article published on 30 June 1999.
Citation: Hughes G, 'Reasonable Design', 1999 (2) The Journal of Information, Law and Technology (JILT). <http://elj.warwick.ac.uk/jilt/99-2/hughes.html>. New citation as at 1/1/04: <http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/1999_2/hughes/>
1. Introduction
The concept of demonstrating 'reasonableness' in the design, proving and operation of products and systems appears to be the key defence against both civil and criminal litigation. Under consumer protection legislation the arguments cover reasonable consumer expectation (do persons generally expect products to contain a millennium bug?) to reasonable producer competence (was there a reasonable alternative design?) (see Howells; 1999 ). The introduction of the UK regulatory concept of 'tolerability' and making risks 'as low as reasonably practicable' (Health and Safety at Work Act 1974, HSE; 1992a and HSE; 1992b ,) has resulted in the need to make 'ALARP arguments' an essential part of a system safety case. A similar concept is used for the control of pollution which requires the use of the 'Best Available Technology/Techniques Not Entailing Excessive Cost (BATNEEC under the Environmental Protection Act 1990). A parallel international development has been the concept of 'As Low As Reasonably Achievable (ALARA), framed by the International Commission on Radiological Protection. Clearly such an approach can also be used for economic risks and financial losses.
The complexity of computer-based systems, which makes complete system testing and/or proving impossible, emphasises the need for a probabilistic (risk-based) approach. This appears to be also consistent with the adversarial UK approach to litigation, where concepts such as 'the balance of probabilities' and 'reasonable doubt' are traditional. The 'millennium bug' represents a very simple and unusual example in this general problem area. It stems from the very small size of early computer memories (for example, 64K of RAM was all that was used in major data acquisition systems in the mid-sixties) in which the use of two-digit dates was an inevitable economy. If anyone had asked if the systems would work beyond the millennium the answer would clearly have been no! - without any difficult assessment. A large body of software/systems was thus introduced incorporating this design limitation and it would have been unreasonable to change without due cause (all changes involve the significant risk of introducing new failures). It could be argued that software that has worked from the mid-sixties has demonstrated its reliability.
This paper provides an engineering perspective and briefly reviews some of the difficulties in demonstrating reasonable (or unreasonable) design in a probabilistic way. It addresses the issues that will provide the grounds for litigation beyond the millennium, when the 'millennium bug' will be regarded as a unique historic problem which whilst expensive was a problem of a trivial technical nature. The problems associated with the justification of complex system designs represent an ongoing challenge.
2. Why are Computers and Software Unreasonable?
Digital computer and electronic systems differ from normal analogue electrical and mechanical systems because of the discontinuous nature of discrete logic. This limits the claims that can be made about future behaviour from successful testing, and makes the effects of changes much less predictable. If we test a computer system on a particular input and find that it works correctly, we cannot be certain that it will work on any other input, even one that is 'close' to the one tested. In other branches of engineering it is generally acceptable to assume continuity. So, for example if a pressure vessel survives a pressure test of 100 Kg per square cm it is reasonable to assume it would survive pressures less than this. In discrete systems there is no simple equivalent to 'pressure' and 'less than'. This reduces the value of system testing and prevents extrapolation from a small set of successful tests to infer correct performance elsewhere. We usually cannot test all possible inputs, since the number of these is generally astronomically large.[ 1 ]
Bespoke computer systems mainly fail because they contain design faults in their application software. (The hardware chips can also contain faults but these are generally discovered by very extensive testing and large usage, although there have been some notable errors discovered in service as illustrated by the fault in recent Pentium processor chip). Many of the faults will have been present from inception but others can be introduced during the changes that are made throughout the system lifetime (there is already evidence of new faults being introduced by 'millennium bug' software changes). Even small programmes can contain design faults and the almost limitless functionality and novelty facilitated by computer-based systems generally leads to complex designs with a high probability of residual faults.
In a wider, systems design, context computers interface with hardware (electrical and mechanical actuators etc) and humans. The validity and security of signals and information communicated in the wider system context represents another important aspect that introduces scope for errors and failures. Recent improvements in communication technology have produced a rapid growth in 'distributed systems' which link resilient autonomous elements e.g. railway signalling, air traffic management and electronic commerce. The present World Wide Web and informal Internet arrangements illustrate both the benefits and the potential danger of such systems. The benefits include an explosion in information (not all good), and an unprecedented ability to interact and work with remote groups. The potential dangers are illustrated by the unreliability of links at higher system usage demands, insecurity (see for example Angel; 1999 ), the threat of virus transmission (sabotage) and loss of confidentiality (interception of email and credit details, junkmail etc.)
The common problem for computer and communication systems is the difficulty in estimating their reliability (the probabilistic metric needed for a risk-based approach) and degree of security (current security practices do not have a probabilistic basis). Reliability is the probability that a system will perform its specified function over a given period of time under defined environmental conditions. In reality a complementary or 'negative' focus is taken to quantify unreliability, which is the direct results of system faults and failure. As already indicated, the main source of unreliability is design faults inherent in their software programmes. Consumers are already aware of the concept of design faults. These can be apparent at initial purchase when the product is ether accepted or rejected, and acceptance often infers legal fitness for purpose. When they become apparent in later usage there is often a 'manufacturer's recall' to remedy the problem, especially if the risks are unacceptable.
In the case of computer-based products, the design faults incorporated in the software can have a long latency because that particular part of the functionality is rarely used. Because of this the importance of such faults is difficulty to assess, on the one hand they could have only a small effect on average reliability on the other they could have catastrophic consequences. The potential consequences of the millennium bug are now of great concern and it has already begun to make its presence felt (see for example < IEC 61508 (draft), a generic standard for all systems, EUROCAE ED-12B and its US counterpart RTCA DO-178B for civil aviation, DefStan 00-55 and DefStan 00-56 for defence procurement.
Unfortunately, there is as yet no 'silver bullet' for reliable design and there remains a significant number of insecurities where the demonstration of the 'reasonableness' of the approach to design and justification of a system could be the only defence in the event of failure.
3. System Failure Modelling and Analysis
Modelling and analysis of complex systems is essential to enable the identification of critical failure modes, or of critical areas of software code, so that they can be 'designed out' or otherwise given special attention. However, for a risk-based approach, an additional crucial aim is the quantification of failure likelihood, which is a severe complicating factor for the models. Failure modelling with decomposition is attractive because it seems reasonable to assume that it is easier to understand and gather data about component behaviour than the behaviour of a system as a whole. For the purposes of discussion, a component will be taken to mean any constitutive part of a system, including human activity. Furthermore, modelling a system as an interacting set of components is intuitive and familiar. However, research into decomposition-based failure modelling has always faced serious difficulties. In a correctly working system the intended functions of components are usually quite specific and restricted. Furthermore a single component interacts with a relatively small number of neighbour components in an understandable fashion, and this is an artefact of the way systems are built - it being difficult to conceive systems which work using complex component interactions. It is these simple component interactions which are traditionally used to construct a failure model, based on formalisms such as failure mode and effect analysis ( IEC 60812 ), fault and event trees ( IEC 61025 ) and block diagrams ( Beasley; 1991 ) ( IEC 61078 ), describing the dependence of the success (failure) of system function on the success (failure) of component function.
Experience has shown that unanticipated routes to system failure are not uncommon ( McDermid; 1993 ). The interesting and problematic property of these unexpected failures is that they often concern collections of components failing together in a correlated fashion. The study of component subsets, as opposed to 'autonomous' components, is inherently more complex because the number of subsets is vastly greater then the number of components. Discrimination of the important subsets is key but is an extremely taxing problem in general. Component failure does not only alter component interactions over existing interaction paths, but can create new interaction paths - including interaction between components, which did not interact prior to failure. The modelling difficulties for design or systematic faults stem from these problems, namely, the necessity of considering related failures of collections of components and not just failure of components in isolation. The idea of incorrect interactions along unintended paths (an example being side effects in software) still apply. Finally components may be working to their requirements and interacting entirely as intended but still produce an incorrect result; the problem being incorrect conception by the system designer.
There have been notable attempts to provide probabilistic models to link component failures for example ( Littlewood; 1979 ), but it is certainly not possible to model system failure solely in terms of independent failure of individual components. However, because it is possible to control the relevant aspects of the system environment - those which affect systematic behaviour, system testing becomes a powerful tool. It is possible to test component collections directly, including the whole system, and it is not necessary to rely on testing individual components. The result is that systematic failure modelling has a different emphasis from traditional approaches. Models are not concerned with analysis of particular types of failure, but rather with demonstrating that faults or failures of any type are rare. Different approaches are possible. A common categorisation is according to the source of evidence used in the model. Evidence of system integrity can be collected either from testing of the product (e.g. statistical software testing) or testing of the process, which created the product.
4. Reliability Estimation
Failure models provide a method of estimating system reliability based on the linking of sub-system or component failure probabilities. At the sub-system/component levels there are a number a ways that reliability can be estimated.
4.1 Empirical Methods
There are a number of direct empirical methods for computer/software reliability estimation which offer the potential of providing hard test evidence of the reliability of a particular implementation (product):
-
Reliability Growth : These estimations are based on the observation of a reducing system failure rate during initial (trial) operation where faults are discovered and removed. There are many different models e.g. ( Jelinski & Moranda; 1972 ) and ( Littlewood & Verrall; 1973 ) which can be used to predict the reliability of the system at the end of the trial when fault discovery is at least infrequent. They normally utilise a prediction of the initial number of faults, which is progressively reduced during the trial. There is a general assumption that 'fixing' a fault reduces the total number and does not affect the mode of operation (which is a very questionable assumption). The models and inevitable restrictions on trial period limit the applicability of the technique to unreliability level targets  10 -2.. 10 -2..
-
Statistical Testing: This is presently a 'black-box' system test in which the normal 'operational' input space is simulated in a statistically correct way. The system is tested against a similar programme or executable specification known as an 'oracle'. The approach has a strong theoretical basis ( Littlewood; 1986 ), ( Miller et al; 1992 ) and statistical models are used to predict the system reliability if the system passes on N tests which have been correctly selected from the operational test profile. It has recently been applied to large safety-critical systems ( May et al; 1995 ) However, researchers have not been able to incorporate system decomposition into prediction models. This is needed to address the issue of system complexity (it is natural to believe that a complex system is more difficult to test that a simple one) and introduce software structure knowledge to make reliability estimation more efficient. This is an active research area, see for example ( Kuball et al; 1999 ).
-
Operational Usage: Reliability can be estimated from use without failure. If a system works correctly for a period then there is a 50:50 chance of the system operating for a further similar period. More generally, using a Bayesian approach,
-
R(t) = (b + t o /b + t 0 + t) a
where a and b are based on Bayesian prior belief of failure rate. They have little effect unless they are strong priors. The technique only provides useful information when a large number of units have been used in a given environment or a small number of units for a time appropriate to the reliability estimate (which could obviously be long). The evidence is of dubious value if the system design or the environment is changed. A good example of this was the failure of the first launch of the Ariane-5 rocket in 1996 which was initiated by the software of an inertial guidance system carried over from Ariane-4 failing to work in the new 'acceleration input environment'. Similarly, the change of 'date environment' at Y2K can be seen as negating the reliability estimates based on prior operational usage.
4.2 Combined Evidence
This more general approach involves a combination of product and process evidence obtained during design and development, which could well include one or more of the empirical methods listed above. A typical software reliability case (or safety case in safety-related applications) will combine evidence from:
-
the quality of the design/development process;
-
testing in a systematic and realistic way;
-
and the analysis of products (known as inspection or static analysis).
Current standards define various combinations of possible approaches that are appropriate for different system/software integrity levels. Table 1 below , derived from IEC 61508 illustrates the concept. In this case SIL stands for safety integrity level. These have the 'loose' relationships to the following unreliability levels:
Safety Integrity Levels 3 & 4 are often referred to as 'safety - critical'.
Whilst the approach defined by Table 1 is plausible, in that design and validation stringency increases with system/software integrity, there is no empirical evidence which correlates the use of the techniques with achieved unreliability of products. In addition, some of the techniques e.g. formal methods can be expensive to apply and there is currently no way of relating integrity to design and validation costs. From a safety regulators standpoint, it is virtually necessary to do almost everything that is conceivable to attempt to claim the 'safety critical' integrity levels. Similar difficulties are apparent with two current software process improvement models, the Capability Maturity Model (CMM) and the Baseline Practices Guide (BPG) developed by the European SPICE project. The CMM provides a detailed method for assessing the maturity of the development software process. It defines a number of process areas, their goals and necessary commitment that is required, the ability to perform, the activities to be performed, monitoring of the implementation and verification, that need to be achieved. However, there is no proven correlation with product integrity.
The DTI/EPSRC FASGEP Project ( Cottam et al; 1994 ) developed an approach based on the fact that the systematic faults embedded in software are introduced during the development process by human activity. It is assumed that the likelihood of fault introduction depends on features of the development process such as its size/complexity, and factors such as the experience and quality of development staff and the difficulties faced by them during development. The output of the model is a probability distribution describing the predicted number of faults introduced up to any point in a development process. It is based on graphical probability models ( Pearl; 1988 , Lauritzen & Spiegelhalter; 1988 ). Currently, the purpose of the model is to guide a software development process prior to testing. In particular, the model can be used to decide when reviews become necessary, based on the predicted fault intensities. The concepts have been further developed in DATUM Project ( Fenton; 1996 ) and in the ongoing CEC funded SERENE Project ( Esprit; 1997 ).
|
Phase/Technique
|
SIL 1
|
SIL 2
|
SIL 3
|
SIL 4
|
|
Specification
|
Informal
|
Informal
|
Semi-formal
|
Formal
|
|
Prototyping
|
Optional
|
Yes
|
Yes
|
Yes
|
|
Design Reviews
|
Peer Review
|
Yes
|
Yes
|
Yes
|
|
Coding
|
HLL[ 2 ] Preferred
|
HLL
|
Safe-Subset HLL
|
Safe-Subset HLL + Design method
|
|
Defensive Code
|
Preferred
|
Yes
|
Yes
|
Yes
|
|
Fault-Tolerant
|
Optional
|
Optional
|
Preferred
|
Yes
|
|
Independent Technical Assessment
|
Optional
|
Optional
|
Preferred
|
Yes
|
|
Static Analysis
|
Optional
|
Optional
|
Yes
|
Yes
|
|
Dynamic Testing
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Independent V & V
|
Optional
|
Yes
|
Yes (Different Department.)
|
Yes (Different Department.)
|
Table 1: Design and validation methods appropriate for systems of increasing integrity ( IEC 61508 )
4.3 Value of Formal Methods and Proof
A possible solution to the design errors manifested in programs/software could be to simply ensure that their programs are completely correct. They are, after all, logical constructs and as such appear to be open to perfectibility. Indeed, there do exist formal mathematical techniques that allow exact correspondence between a specification for a program, and the program itself, to be asserted with certainty (assuming the proof techniques are themselves valid and applied correctly). Following such a proof, it is tempting to claim that the software is completely fault-free: at least there should be a guarantee that the software would do what the specification says it should do - no more, no less. Unfortunately for this to be true, the specification involved in the proof would need to be a formal object itself, which is a correct embodiment of the high-level 'engineering requirements' - what we really want the software to do. In fact, experience suggests that a high proportion of serious design faults arise as a result of misunderstandings of these more informal (and rich) system requirements. Such faults become embedded in the formal specification, which is then imperfect, and results in imperfect programs written from that specification.
For these reasons it is very rarely possible to assert credibly that software is completely reliable and that failures are impossible; indeed, it is unlikely that such claims for complete perfection can be sustained even for programs of only relatively modest complexity. This is not to say that formal proof of this kind has no value. On the contrary, it would clearly be useful to know that a program is completely free of implementation faults (those that arise from the activities involved in turning the specification into the executable program); but it does mean that we are still left with the task of evaluating the impact upon safety of possible faults in the specification. Formal methods can even help here, for example by checking for consistency of a specification.
Assuming for the moment that a formal specification can be written which accurately captures the engineering requirements, the feasibility of proving the functionality of the source code depends on the style and structure adopted during design. Formal verification of the functionality of software designed from the outset with formal verification in mind is certainly feasible, even for quite large programs. The cost is high, but not excessive compared with, for example, the cost of the sort of testing normally expected for safety- critical systems. The problem is that most real-time software has structures that are inherently difficult to verify, and functionality that depends on non-functional properties such as scheduling and memory usage. Whilst these can be modelled formally, they tend to be difficult to analyse. Thus although it is possible to perform full formal verification in some circumstances, in many projects it is impractical to do so. Of course, it could be argued that complete correctness, although desirable, is not necessary, even for safety-critical software. Some of the failure modes of even safety-critical systems will be ones with relatively benign consequences, and others may be masked by built-in logical redundancy, so that it would be sufficient to know that there were no faults present.
5. The Role of Humans in System Design and Operation
Most systems involve interactions between Man and Machine with the machines designed to enhance human capabilities whilst leaving the human in overall control. The machines attempt to reduce the scope for human errors associated with:
-
Omission - doesn't do what's required;
-
Commission - Does what isn't required (in the extreme this can be sabotage);
-
Stress - 'Man is not a Machine, at least not a machine like Machines made by Man'.
The importance of organisation and human factors in risk assessment is recognised ( HSE; 1992c ) and the overall aim is to obtain a 'balance' between automation and human action. Simplifying operator tasks by the utilisation of data analysis, control and protection systems transfers the problem to the designer and maintainer of the new systems who can also make errors - and who will need to be supported by a range of design and configuration control tools to improve the design and maintenance management etc. etc. It is thus a demonstration of this balance that is required to demonstrate the overall reasonableness of the approach. Clearly, automation can provide very significant benefits to performance and safety even when the new systems are not totally reliable and this could provide a sound defence in the event of failure. However, although automation is generally welcomed, increasing the degree of automation is not guaranteed to improve system operation and reliability. It tends to reduce the operator's understanding of the system as well as possibly reducing his/her involvement to that of a monitoring role, perhaps even to the point of boredom. It is known that humans are poor at vigilance tasks, especially when checking for low frequency events ( Wickens; 1984 ).
Survey work with flight deck crew ( Noyes et al; 1995 ) indicated that greater automation and improved system reliability generally result in a reduction in the extent of the crews' interactions with the aircraft systems. This reduction in 'hands on' operation tends to lead to a decrease in the crew's knowledge and experience of detailed system function. Although all the relevant flight information is present within the system, there is no procedural or operational need to interact with it, and this lack of interaction results in crews having less need to cross-check and discuss aspects of the flight with each other. This can result in a subsequent loss of situation awareness - a concept described as 'peripheralisation' by ( Satchell; 1993 ) and others. In the aviation world, this aspect of automation is recognised as being of increasing concern ( James et al; 1991 ). However, situation awareness is not simply awareness of system states, but also extends to include the interpretation of data pertaining to these systems ( Pew; 1994 ). For example, some current civil aircraft warning systems are programmed to attract the crew's attention only when parameters pass out of limits, i.e. beyond pre-determined fixed thresholds. Consequently, no failures mean that there are no distractions for the crew, but also no information. It has been pointed out by ( Wiener; 1987 ) that human operators must continually exercise their capacity to analyse, seek novel solutions and extrapolate beyond the current situation, and automation as a general rule does not always allow or encourage this.
A simple domestic example is the introduction of Automatic Braking Systems (ABS) on modern cars. These systems obviously improve safety in general, but there may be maintenance concerns in the future. Also, a driver who becomes used to the automation must be more likely to have an accident in a non-ABS car and it would be interesting to see if the supplier of ABS had any liability in this respect!
6. Development of ALARP Arguments
The essence of a current demonstration of ALARP is to show that the costs of improving safety (or reducing risks of any type) would be disproportionate to the benefits that would accrue from implementing the improvement. The potential major benefits obtained by the introduction of improved (new) technology often appears to be ignored. The probabilistic definition of ALARP targets has lead to a tendency to emphasise this cost/benefit aspect by using Probabilistic Safety Analysis (PSA) to estimate risk reduction and compare this with the costs. The major problems are separating out costs and benefits directly attributable to safety and in dealing with uncertainties and judgements incorporated in PSA compounded with those of the costing exercise. However, whilst the approach is normally considered to be essentially 'quantitative' the uncertainties usually require that 'qualitative' factors are also considered, and judged by enforcing direct comparison against 'best practice' and deterministic safety criteria. Included in this are factors associated with design and organisational management, procedures and staff competence/training.
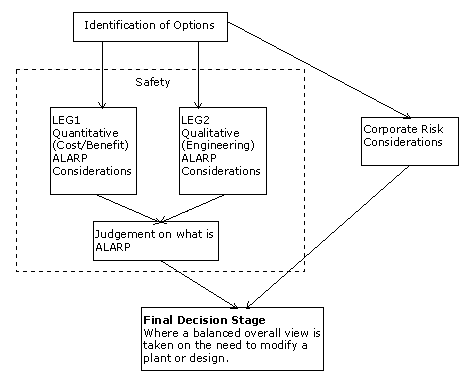
An important aspect of this 'two leg' approach is that the outcomes of the two assessments should provide consistent conclusions. (The concept is similar to the 'combined evidence' approach described above). For example, the Nuclear Sector apparently treats the legs as separate activities, which are only combined at the ALARP Judgement stage. In addition corporate risk factors are often included in a final decision stage.
Thus there is a tendency for the Final Decision Stage to be relatively simple and for any necessary weighting of the different results to be performed by humans (probably as members of a committee or expert group). The very important judgements incorporated in the deterministic and probabilistic analyses may be informally reviewed but in general the final decision is based on an acceptance of the methods and previous analyses.
The decision process is illustrated in the block diagram below.
Thus it appears to be current practice to base ALARP decisions on two apparently diverse forms of pre-processed evidence. However, what is certain is that the two forms of evidence were derived from a common data bank containing empirical, historical, predicted (derived) and subjective (qualitative) components. Because of this it may be unjustified to assume that the two pieces of evidence are in any way orthogonal. Indeed both elements may be derived from one common heavily weighted factor. Clearly the processes represent one particular approach to making a judgement which may be seen as having the following weaknesses/vulnerabilities:-
-
judgement and subjective factors are used at different places in the process not merely at the final stage;
-
the judgements and weightings are not easily traceable;
-
the diverse arms of the processes are likely to depend on the same data;
-
the rules, heuristics and standards may not be consistent with the available historic data i.e. they could not be induced in a formal way from available evidence;
-
the cost models used are usually simple and given a lower degree of importance cf. Safety assessment.
Even for a design or modification with a strong quantified Leg 2 it would also be necessary to show that the management of risk and engineering concepts are sound. At present, this means that it is not usually possible to lay down a formula, or a set of definitive rules for decision making: the process of risk management depends on human judgement, in which many disparate factors, which cannot always be reduced to a common currency, have to be considered.
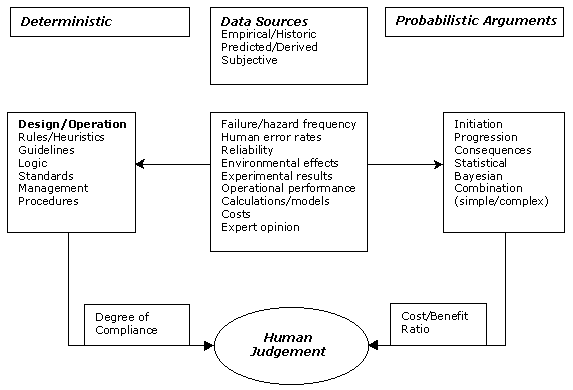
The following diagram could more accurately represent the actual processes.
Clearly it could be argued that new approaches are needed to make such 'judgmental vagueness' ALARP. However, the 'soundness' of management processes and engineering concepts is not well modelled in any way and some form (possibly probabilistic) of common currency may be needed to make any progress in formalising such aspects.
The present approach is clearly difficult and there would appear to be number ways in which the Judgmental Framework could be improved, including:
1. Induction of rules from history/previous cases - this will ensure they have a real foundation and that new systems can be designed to achieve conformance;
2. Development of probabilistic analysis/argument to include deduction of 'soft' probabilities and a richer set of interactions/factors/influences;
3. Use new advanced methods to model management processes, engineering concepts and costs, in addition to safety/economic risk assessment.
Transferring these expert processes to a legal framework will be difficult and possibly the only way forward is to have judgements assisted by Artificial Intelligence (AI) methods. A start to this has already been made in, for example, the combination of evidence using graphical probability networks outlined in Section 4.2 above. Other relevant AI methods include Case Based Reasoning (CBR) and Data Mining.
A case-based reasoner can act as an aid to make decisions based on the decisions made in the past in similar cases. In a Cost-Benefit environment when trying to resolve conflict and base decisions on two disparate metrics, being able to manipulate and use knowledge about what occurred in similar cases in the past and what decisions were made can prove to be, in essence a useful aid. The process can be augmented by adapting the solution so that it more closely matches the requirements of the current problem. CBR can as such help to highlight good engineering practices within safety critical domains and deterministic safety considerations, which should be given due emphasis, based on the past trends highlighted by such methods.
The work of Schank and Abelson in 1977 is widely held to be the origin of CBR. They proposed that our general knowledge about situations be recorded as scripts that allow us to set up expectations and perform inferences. The approach would align well with concepts of legal precedence.
CBR is a typically cyclic process:
1. RETRIEVE the most similar cases;
2. REUSE the cases to attempt to solve the problem;
3. REVISE the proposed solution if necessary, and
4. RETAIN the new solution as part of a new case.
The cycle and resulting CBR application can be used as a decision support tool with human intervention. ( Dattani et al; 1996 ).
7. Conclusions
Computer-based systems have introduced a step change in complexity and at the same time greatly reduced the time to market of new products. They are almost certain to contain design errors which could cause malfunction or failure in the environment for which they were designed. The demonstration by designers/suppliers or users that reasonable steps have been taken to prevent failure and are consistent with the best practice of the time will continue to be a problem. It would seem to be sensible for engineers and scientists to work with the legal profession to possibly develop a set of decision support tools to facilitate a just legal framework, which recognises the fundamental uncertainties in the processes involved. These uncertainties are not really addressed by today's standards/guidelines and product certification processes.
References
Angel J (1999) 'Why use Digital Signatures for Electronic Commerce?' Journal of Information, Law and Technology (JILT) 1999 (2). < http://elj.warwick.ac.uk/jilt/99-2/angel.html >.
Beasley M (1991) Reliability for Engineers (London: Macmillan).
Cottam M, et al (1994) 'Fault Analysis of the Software Generation Process - The FASGEP Project,' Proceedings of the Safety and Reliability Society Symposium: Risk Management and Critical Protective Systems , Altrincham, UK October 1994.
Dattani, I, Magaldi, R V and Bramer, M A (1996) 'A Review and Evaluation of the Application of Case-Based Reasoning (CBR) Technology in Aircraft Maintenance' ES96: Research and Development in Expert Systems XIII. SGES Publications.
DefStan 00-55 (1995) Procurement of safety critical software in defence equipment. (Ministry of Defence, UK).
DefStan 00-56 (1995) Requirements for the analysis of safety critical hazards (Ministry of Defence, UK).
Esprit Project 22187 (1997) SERENE Safety and Risk Evaluation using Bayesian Nets.
EUROCAE ED-12B (1992) (and its US equivalent RTCA/DO-178B). Software considerations in airborne systems and equipment certification (EUROCAE).
Fenton N E (1995) 'The role of measurement in software safety assessment,' CSR/ENCRES Conference Bruges 1995 (proceedings published by Springer Verlag, 1996).
Howells G (1999) 'The Millennium Bug and Product Liability' Journal of Information, Law and Technology (JILT) 1999 (2). <http://elj.warwick.ac.uk/jilt/99-2/howells.html>.
HSE (1992a) 'The Tolerability of Risk from Nuclear Power Stations (TOR)' Health and Safety Executive (London: HMSO).
HSE (1992b) 'A Guide to the Offshore Installations (Safety Case) Regulations', Health and Safety Executive (London: HMSO).
HSE (1992c) 'Organisational, Management and Human factors in Quantified risk Assessment', Reports 33/1992 & 34/1992. Health and Safety Executive (London: HMSO).
Hughes G, May J and Noyes J (1997) 'Designing for Safety: Current Activities at the University of Bristol and Future Directions' Safety Critical Systems Symposium Brighton, February 1997, Springer Verlag, ISBN 3-540-76134-9.
James M et al (1991) 'Pilot attitudes to automation', in Proceedings of the Sixth International Symposium on Aviation Psychology pp 192 - 197 (Ohio State University, Columbus).
IEC 60812 (1985) Guide FMEA to and FEMCA ( BS 5760 Pt 5) International Electrotechnical Commission, Geneva.
IEC 61025 (1990) Guide to fault Tree Analysis (BS 5760 pt 7). International Electrotechnical Commission, Geneva.
IEC 61078 (1991) Guide to the Block Diagram Technique (BS 5760 Pt 9). International Electrotechnical Commission, Geneva.
IEC 61508 (1998) Draft Standard on 'Functional safety of electrical/electronic/programmable electronic safety-related systems'. International Electrotechnical Commission, Geneva.
Jelinski Z and Moranda P B (1972), Software Reliability research, statistical computer performance evaluation , Freiberger W pp 465-484 (New York: Academic Press).
Kuball S, May J and Hughes G (1999) 'Structural Software Reliability Estimation,' paper to be given at Safecomp 99 , Toulouse, September 1999, Conference proceedings to be published by Springer Verlag.
Lauritzen S L and Spiegelhalter D J (1988) 'Local Computations with Probabilities on Graphical Structures and Their Application to Expert Systems' J. Royal Statistical Society B Vol. 50 no. 2.
Littlewood B (1979) 'Software reliability model for modular programme structure,' IEEE Transactions on Reliability , Vol. R-28 no. 3 pp.241-246.
Littlewood B (1986), 'How reliable is a program that has never failed?' ALVEY Club Newsletter Issue 4, December 1986.
Littlewood B and Verrall J L (1973),) 'A Bayesian Reliability Growth Model for Computer Software,' Journal Royal Statistical Society , Vol. C-22 no. 3 pp. 332-346.
May J, Hughes G and Lunn A D (1995) 'Reliability Estimation from Appropriate Testing of Plant Protection Software,' IEE Software Engineering Journal , Nov. 1995.
McCormick N J (1981) Reliability and Risk Analysis (New York: Academic Press).
McDermid J (1993). 'Issues in the Development of Safety-Critical Systems,' in Safety-critical Systems: Current Issues, Techniques and Standards (F Redmill & T Anderson, eds.) (London: Chapman & Hall).
Miller W M, Morrell L J, Noonan R E, Park S K, Nicol D M, Murrill B W, and Voas J M (1992), 'Estimating the probability of when testing reveals no failures,' IEEE Trans on Software Engineering Vol. 18 no. 1.
Noyes J M, Starr A F, Frankish C R and Rankin J A (1995). 'Aircraft warning systems: Application of model-based reasoning techniques,' Ergonomics , Vol. 38 no. 11 pp 2432-2445.
Pearl J (1988). Probabilistic Reasoning in Intelligent Systems , (San Mateo: Morgan Kaufmann).
Pew R W (1994). 'Situation Awareness: The buzzword of the '90s', CSERIAC Gateway , Vol. 5 no. 1 pp 1-16.
Satchell P (1993). Cockpit Monitoring and Alerting Systems (Aldershot: Ashgate).
Schank, R C and Abelson R P (1977) Scripts, Plans, Goals and Understanding . (New Jersey, US: Erlbaum Hillsdale).
Wickens C D (1984). Engineering psychology and human performance . (Columbus, Ohio: Charles E. Merrill).
Wiener E L (1987). 'Management of human error by design,' In Proceedings of the 1st Conference on Human Error Avoidance Techniques , Paper 872505 pp 7-11, (SAE International. Warrendale, PA).
Footnotes
1 . If a computer has 50 inputs, each of which can have 100 discrete values, there are 100 50 possible different inputs to the software. If each case could be tested in 1 second, a complete test would take 10 92 years.
2 . HLL means High Level (programming) Language such as Ada or C.
|