An Automaic System for
Collecting Crime Information on the the Internet
Patrick S. Chen
Department of Information Management
Central Police University
Taiwan
[email protected]
The author wishes to thank Anthony Chu for his programming work in the research project and the anonymous referees for their valuable advice in improving the quality of the paper.
Abstract
This paper describes the operation of an automatic crime information collecting system, called e-Detective , which is developed by the author. It is one of the first special-purpose search engines ever developed. Since searching suspected crime information is a difficult task, the system is designed from a practical point of view and several special functions are implemented for it. The system is composed of a Web crawler, a lexicographical parser, a database of search concepts, a match program, a natural- language processor, and a data manager. In order to search crime information, Web pages are first analyzed lexicographically and semantically by the computer, then verified by human experts. Two experiments are reported to demonstrate the way in which the system works. The result reveals that the retrieval precision of our system is superior to other commercially available search engines. Thus, it is able to assist law enforcement agencies in finding information to investigate cybercrime.
Keywords: Cybercrime, e-Detective , Internet, Computer Crime
This is a Refereed article published on 31 October 2000.
Citation: Chen P, 'An Automatic System for Collecting Crime on the Internet', 2000 (3) The Journal of Information, Law and Technology (JILT). <http://elj.warwick.ac.uk/jilt/00-3/chen.html>. New citation as at 1/1/04: <http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/2000_3/chen/>
1. Introduction
With the popularity of the Internet, a large quantity of information is provided on it. Just the amount of textual data available is estimated in the order of one terabyte, without mentioning other media such as images, audio, and video ( Baeza-Yates, 1998 ). While Internet provides us with knowledge, opportunity, and convenience of living, the abuse of network comes with it. Since Internet-related legislation is not yet mature and the infrastructure of information society is still under construction, there is a room for illegal opportunists to commit crime, which is commonly known as cybercrime .
The first step to investigate crime cases is to collect suspected information. However, on the Internet it cannot be easily done due to its enormous volume. The Uniform Resource Locator (URL) mechanism of the World Wide Web (WWW, or Web for short), that enables data search by address, does not support our search with special intention effectively. With such diverse contents and enormous volume of information on the Web, retrieving data we need is far from assured ( Filman and Pena-Mora 1998 ), ( Konopnicki & Shmueli 1995 ). One of the most primitive ways to investigate cybercrime is to download Web pages according to their URLs and analyze them manually. This method is both labor-intensive and inefficient because finding suspected data from millions of Web pages is as difficult as finding a needle from a haystack. Therefore, it makes sense to develop a computer system to search crime information automatically. In our research project we have designed and implemented an electronic detective system, the e-Detective , which could help us in doing this job.
The e-Detective system is a proprietary search engine, which differs from general-purpose search engines, such as AltaVista , Yahoo or Openfind in several aspects:
1) It is specially designed for the purpose of collecting crime information;
2) Enhancement of search accuracy is made for collecting specific information. This system is attached with several subject-specific thesauri, databases of term phrases with respect to specific crime types that could help us in analyzing crime data patterns.
With the help of this system, we expect to assist law enforcement agencies to keep the order of cyber society so that the Internet remains a platform for well-beings, not a place where the illegal people perform their activities.
The e-Detective system is one of the first special-purpose search engines ( Chen, 1998 ), which can fetch data from the Internet automatically for specific purpose. The way the system works is also different from that of general-purpose search engines. This system is developed for law enforcement and lawyer firms that conduct highly intelligent retrieval tasks to find information so as to solve difficult problems. Typical examples of these tasks are to find suspected information on the Web about:
1) Child pornography;
2) Drug trafficking;
3) Infringement of intellectual property, e.g. piracy of copy rights; and
4) Underground monetary institutions, etc.
In order to get an understanding of effectiveness of the tool we have carried out a series of system tests. Assessment of the search results reveals that the system achieves high retrieval precision. Thus, this system has proven to be capable of carrying out retrieval tasks to find useful information for our purpose.
The rest of contents is organised as follows: Section 2 classifies illegal information to be searched on the Internet. Section 3 describes the system architecture. Section 4 deals with system implementation where we describe the technique used in implementing the main components of the system. The use of a new method for natural language processing (NLP) is worthy of mentioning. Section 5 reports the operation of system with the help of two experiments. We also evaluate retrieval efficacy in the notion of precision and recall. Last section summarizes the contribution of research and offers some discussions.
2. Classification of Illegal information on the Internet
In order to find the clue of a crime, the first step is to collect information, denoted as crime information in this paper. Though the information can be published in different ways, we distinguish two types of crime information on the Internet:
Type I : The behaviour of diffusing certain kinds of information on the Internet constitutes a crime. This kind of information is, for example, fraud, intimidation, defamation, infringement of copyrights, etc.
Type II : The behaviour of diffusing certain kinds of information on the Internet is in itself not a crime, but is able to help others to commit crime. For example, teaching method of making bombs on the Web is protected under the speech freedom, but such action would enable others to commit crime. Whether this kind of behavior constitutes aiding or abetting, depends on the mens rea . If no actus reus is involved, it is not punishable.
Based on the nature of information, we are only allowed to collect information that is punishable, i.e., the information of Type I. Since the diffusion of this kind of information constitutes a part of crime, it is the object to be collected by our system, denoted as our search intention.
After having determined the type of information to be collected, we shall translate this kind of information into an adequate form that a computer system can process. In the next section we are going to describe the architecture of such a system that will carry out the task of data searching.
3. System Architecture
The system is composed of three main components: A Web crawler fetches pages from the Internet one by one; a match program compares the pages with the search intention; and a data manager is responsible for the management of search results. Principles for constructing such a search engine include:
1) The information needed by law enforcement agencies will be prepared through a special process. This information need will, then, be analyzed and processed into a form representing the search intention of the law enforcement agency;
2) A Web crawler is used to collect data on the Internet;
3) A program is made to compare the search intention with Web pages lexicographically to filter out irrelevant pages;
4) Semantic analysis of the selected pages shall be done to identify the pages containing crime information;
5) Analysis of search results based on human expertise is necessary;
6) Facilities for organizing and managing search results should be provided.
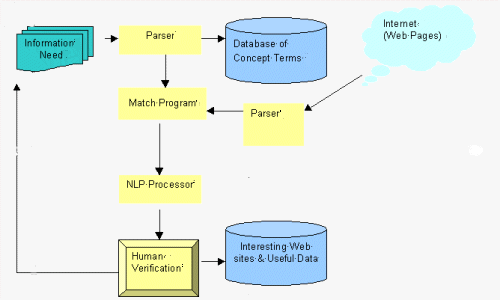
Based on the above principles, we draw up a diagram (Figure 1) to demonstrate the e-Detective system.
Figure 1: Architecture of the e-Detective System
The way in which e-Detective works is described briefly as follows: A parser transforms narrative descriptions of the law enforcement agency into a set of concept terms representing the search intention of the agency. A Web crawler fetches data from the Internet, and the parser also transforms the data into a set of concept terms. A match program compares the two sets of concept terms. The best-matched pages will first be analyzed semantically by a natural language processor (NLP) and, then, by human experts. Thereafter, relevant pages and Web sites are stored together with their addresses. If a page is verified as containing crime information, it will be processed automatically to abstract new concept terms that are to be added to the database for supporting further search. Therefore, the e-Detective is a continuously evolving system.
4. System Implementation
We develop the e-Detective system by employing a rigorous methodology. In the following subsections we describe its four main components.
4.1 The Parser
A parser is principally a lexicographical analyzer that identifies concept terms contained in a text. A list of stop-words is used to filter out the words of less significance.
4.2 The Database of Concept Terms
We assign a weight to a term to denote its significance (e.g. its relevance to a subject). The term is stored together with its weight in database. Thus, the content of a database is a list of 2-tuples (t, w) with t a term phrase and w its associated weight. The databases are classified according to their specific subjects, e.g., politics, economics or electronics.
4.3 The Match Program
A match program is used to compare terms contained in a database, which is related to a certain subject, with the terms appearing in a Web page. Output of the match program is the accumulated weight of the Web page. If a term of the database also appears in a Web page, the weight of the term will be added to the accumulated weight of the page. Pages with heavier weight are considered as relevant for the subject. We also suggest some inference rules to be applied in the match procedure ( Chen, 1994 ). These rules are used to handle the problem of synonyms, acronyms, and so on.
4.4 The NLP Processor
While the parser processes texts lexicographically, the NLP processor analyzes them semantically. Main function of the match program is to filter out irrelevant Web pages such that the search space can be narrowed. After lexicographical analysis only a limited number of pages are chosen for semantic analysis. In order to understand the meaning of the text, we have suggested a Semanto-Syntactical parsing method, which will be described briefly here. Since natural language processing is not the main topic of this paper, interested readers may refer to Chen et al.( 1995 ) for further details.
A Semanto-Syntactical analyzer works according to a head-modifier principle. Tesniere (1959), mentioned in the theory of dependency grammar that every language construct consists of two parts: A + B (head and modifier). The head is defined as follows:
Definition: Head-Operand. In a language construct 'A + B', A is the head (operator) of B (operand), if:
the meaning of B is such a function that narrows the meaning of 'A + B';
and the syntactical property of the whole construct 'A + B' coincides with that of the category of A.
With this postulate, we are able to develop a language parser. The heads of 13 language constructs (of English) listed in Figure 2 can be determined unambiguously:
|
No.
|
Constructs
|
Head
|
Modifier
|
|
1
|
V+XP(NP, PP, S, AP, AdvP)
|
V
|
XP
|
|
2
|
P+XP(NP, AP, S)
|
P
|
XP
|
|
3
|
A(Predicative)+XP(NP, PP, S)
|
A
|
XP
|
|
4
|
Aux+VP
|
Aux
|
VP
|
|
5
|
Comp+S
|
Comp
|
S
|
|
6
|
InfV(VP)+NP(Subject)
|
InfV
|
NP
|
|
7
|
Det+N
|
N
|
Det
|
|
8
|
A(Attributive)+N
|
N
|
A
|
|
9
|
Part+XP(NP,AP,PP)
|
XP
|
Part
|
|
10
|
Adv+XP(NP,AP,PP)
|
XP
|
Adv
|
|
11
|
V+Adv
|
V
|
Adv
|
|
12
|
NP+XP(PP,S)
|
NP
|
XP
|
|
13
|
N1+N
|
N
|
N1
|
|
A (Adjective)
|
Adv (Adverb)
|
AdvP (Adv. Phrase)
|
AP (Adj. Phrase)
|
|
Comp (Conjunctive)
|
Det (Determinant)
|
N, N1 (Noun)
|
InfV (Infinite Verb)
|
|
NP (Noun Phrase)
|
P (Preposition)
|
Part (Particle)
|
PP (Prep. Phrase)
|
|
S (Sentence)
|
V (Verb)
|
VP (Verb Phrase)
|
XP (as indicated in the parenthesis)
|
Figure 2: Thirteen language constructs with their headers
After parsing, a sentence will be decomposed into several constructs. We will obtain a syntax tree together with a set of heads and modifiers. The meaning of a sentence may be captured by its concept terms that are constructed in the following way:
1) Heads belonging to the categories of noun, verbs, and adjectives are concept terms because they are semantic bearers;
2) Heads that belong to the categories of prepositions and conjunctives, together with '', are connectors that combine concept terms to form expressions. The '' is called the null connector ( Bruza and van der Weide, 1991 ), which is used to concatenate two or more nouns. The system for formation of expressions has a simple syntax:
Expression Term {Connector Expression}*
Term String
Connector | to | from | and | .
Where a term is associated with a noun, a verb, or an adjective and a connector determines the type of relationship between two terms.
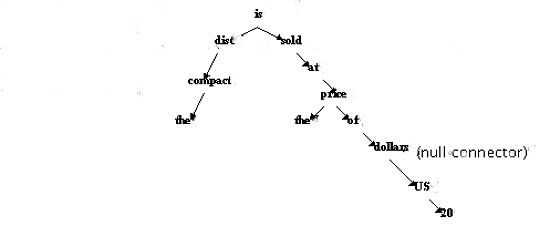
For example, let us analyze the sentence ' The compact disc is sold at the price of 20 dollars'.
Figure 3 A parsed tree of the sentence 'The compact disc is sold at the price of 20 dollars'.
The analyzed syntax tree is illustrated in Figure 3 and the heads can be read from the left column of Figure 4.
|
Head
|
Modifier
|
|
is sold :
|
disc
|
|
disc :
|
the compact
|
|
at :
|
the price
|
|
price :
|
of 20 US dollars
|
|
of :
|
20 US dollars
|
|
US dollars :
|
20
|
Figure 4: Heads and modifiers of the sentence 'The compact disc is sold at the price of 20 dollars'.
We are going to ignore the verb to construct a set of noun phrases as they do in the community of IR. The concept terms obtained from the sentence are { disc, compact disc, price, US dollars, 20 US dollars, price of 20 US dollars }. In this way we are able to extract e.g. ' price of 20 US dollars' . If we substitute ' of ' with ':', we obtain ' price: 20 US dollars ', which gives us important information, the price. In traditional methods we extract keywords by counting their occurrences, we may obtain, e.g. ' US dollars ', but not ' 20 US dollars ' in case the occurrence frequency of the latter is not above a certain threshold. In other words, the Semanto-Syntactical parsing could take into account semantics of sentences.
5. Operating with the System
In this section we describe a way of collecting crime information with the help of e-Detective and the evaluation of retrieval effectiveness. We provide a detailed report of the experiments that are done in three steps:
-
Construction of a database of concept terms associated with their weights;
-
Determination of the threshold of the accumulated weight for Web pages to be retrieved;
-
Semantic analysis for the pages with accumulated weight above the threshold. ( Gorden and Pathak, 1999 ) argued that there are several criteria to evaluate search tools, e.g., retrieval speed, friendliness of user interface, easiness in browsing search results, assistance in formulating queries, and so on. In our system we emphasize the relevance of retrieved data for search intentions in the notion of precision and recall ( Salton and McGill, 1983 ), because they are the most important indicia showing the effectiveness of a search tool.
Several experiments have been made for evaluating our system, we report two of them in this paper. In the first experiment, we try to collect information of child pornography that is illegal in most countries. The second experiment is much more appealing since it cannot be done merely by lexicographical method. Here, we try to collect the information of selling pirated compact discs (CD), which may be identified by, e.g. unreasonably low price.
To report a well-conducted experiment, it is necessary to obtain meaningful measures of performance. That is, the experiment should follow standard design and conform to well-known measurements, such as recall-precision curve as we do in the field of Information Retrieval, to allow results to be evaluated in a familiar context. In addition, precision and recall are computed at various cut-off values.
5.1 Searching Crime Information of Child Pornography
We report the crime investigation process, which is done in the following steps:
1) Construction of a Database of Search Concepts
In the first step we are going to construct a database of search concepts. A search concept recorded in the database has the form of ( term, weight ). The concept terms are selected from representative pages judged by human experts, and the weights are determined by their relative frequencies appearing on the pages. In this case, we extract 336 keywords from 97 representative pages of child pornography provided by domain experts;
2) Determination of the Threshold
In order to determine the threshold of accumulated weight for a Web page of child pornography, we randomly choose pages from classified Web sites to form a pool of samples. Then, we insert the above-mentioned 97 representative pages into the pool. Note that the representative pages are distinct from the pages in the pool. The pool serves as input for the system to evaluate retrieval precision and recall. Based on the precision-recall curve we can determine an adequate threshold for retrieving crime information.
In total, 36 Web sites are selected from 6 local portal sites, namely Dreamer , Hinet , Kimo , Openfind , Todo and Yam . These Web sites are classified under 'Sex', 'Adult', 'Women & Girls', 'Porno', 'Fortune', 'Pastime', 'Teenager', and 'Partnership'. Note that no Web page is selected twice. In total, 5267 pages are randomly chosen from these Web sites.
| |
Portal site
|
No of
Web site
|
Pages
chosen
|
|
Portal site
|
No of
Web site
|
Pages
chosen
|
|
1
|
Dreamer
|
1
|
2
|
21
|
SinaNet
|
1
|
9
|
|
2
|
|
2
|
16
|
22
|
|
2
|
6
|
|
3
|
|
3
|
14
|
23
|
|
3
|
2
|
|
4
|
|
4
|
1
|
24
|
|
4
|
1
|
|
5
|
|
5
|
30
|
25
|
|
5
|
1
|
|
6
|
Hinet
|
1
|
1
|
26
|
Todo
|
1
|
31
|
|
7
|
|
2
|
5
|
27
|
|
2
|
19
|
|
8
|
|
3
|
1
|
28
|
|
3
|
15
|
|
9
|
|
4
|
5
|
29
|
|
4
|
6
|
|
10
|
|
5
|
22
|
30
|
|
5
|
1
|
|
11
|
Kimo
|
1
|
155
|
31
|
Yam
|
1
|
128
|
|
12
|
|
2
|
131
|
32
|
Yahoo!
|
1
|
169
|
|
13
|
|
3
|
9
|
33
|
|
2
|
1
|
|
14
|
|
4
|
11
|
34
|
|
3
|
1
|
|
15
|
|
5
|
5
|
35
|
|
4
|
2
|
|
16
|
Openfind
|
1
|
1
|
36
|
|
5
|
160
|
|
17
|
|
2
|
1
|
|
|
|
|
|
18
|
|
3
|
2
|
|
|
|
|
|
19
|
|
4
|
5
|
|
|
|
|
|
20
|
|
5
|
4298
|
Total
|
|
|
5267
|
Figure 5: Number of Web sites chosen from portal sites
|
Accumulate d weight of a page (¥)
|
Pages selected
by our system
|
Correct pages judged by
domain expert
|
Pages with
weight ¥ the weight indicated in column 1
|
Precision
|
Recall
|
|
0.00
|
139
|
139
|
5261
|
2.64
|
100.00
|
|
0.14
|
90
|
139
|
1334
|
6.75
|
64.75
|
|
0.16
|
89
|
139
|
1278
|
6.96
|
64.03
|
|
0.21
|
87
|
139
|
1150
|
7.57
|
62.59
|
|
0.26
|
86
|
139
|
1065
|
8.08
|
61.87
|
|
0.27
|
85
|
139
|
1059
|
8.03
|
61.15
|
|
0.29
|
84
|
139
|
1040
|
8.08
|
60.43
|
|
0.33
|
83
|
139
|
982
|
8.45
|
59.71
|
|
0.34
|
80
|
139
|
974
|
8.21
|
57.55
|
|
0.36
|
79
|
139
|
953
|
8.29
|
56.83
|
|
ò
ò
ò
|
ò
ò
ò
|
ò
ò
ò
|
ò
ò
ò
|
ò
ò
ò
|
ò
ò
ò
|
|
3.98
|
34
|
139
|
248
|
13.71
|
24.46
|
|
4.27
|
33
|
139
|
235
|
14.04
|
23.74
|
|
4.34
|
31
|
139
|
231
|
13.42
|
22.30
|
|
ò
ò
ò
|
ò
ò
ò
|
ò
ò
ò
|
ò
ò
ò
|
ò
ò
ò
|
ò
ò
ò
|
|
35.01
|
5
|
139
|
112
|
4.46
|
3.60
|
|
44.47
|
4
|
139
|
91
|
4.40
|
2.88
|
|
74.50
|
3
|
139
|
26
|
11.54
|
2.16
|
|
82.59
|
2
|
139
|
13
|
15.38
|
1.44
|
|
87.99
|
1
|
139
|
10
|
10.00
|
0.72
|
Figure 6: Determination of Threshold Based on the Precision/Recall
From Figure 6 we learn that the precision at the accumulated weight 4.27 is a local minimum. It is legitimate to select the accumulated weight of 4.27 as a threshold where we obtain precision of 14.04 and recall of 23.74.
3) Evaluation of the Retrieval Effectiveness
From our experiment we learn that the retrieval precision of 14.04% is not satisfactory. The reason for it is that most pages of child pornography are presented in a form of image. The meaning of the few words attached to these pictures is difficult to be captured by merely keyword comparison. Semantic analysis is then used by means of natural language processing. However, the work done so far is useful since it narrows the search space to a large extent.
Next, we fetch the texts of the pages above the threshold from the Web for parsing semantically. We use semanto-syntactical method to parse these texts. A text will be analyzed from sentence to sentence so as to determine whether it bears the semantic of ' age under 16 ', ' school children 'and the like. If the meaning of any sentence is relevant for these concepts, the page containing such sentences will be selected for further investigation by human experts.
| |
Portal site
|
Sequence
Number of
Web sites
|
Pages
chosen
|
Relevance
judged by
human experts
|
Relevance
judged by the system
|
|
|
1
|
Dreamer
|
1
|
2
|
Yes
|
no
|
*Foreign language
|
|
2
|
|
2
|
16
|
Yes
|
no
|
|
|
3
|
|
3
|
14
|
Yes
|
no
|
|
|
4
|
|
4
|
1
|
No
|
no
|
|
|
5
|
|
5
|
30
|
No
|
no
|
*unrecognizable code
|
|
6
|
Hinet
|
1
|
1
|
No
|
no
|
|
|
7
|
|
2
|
5
|
No
|
no
|
|
|
8
|
|
3
|
1
|
Yes
|
no
|
|
|
9
|
|
4
|
5
|
Yes
|
no
|
|
|
10
|
|
5
|
22
|
No
|
no
|
|
|
11
|
Kimo
|
1
|
155
|
Yes
|
no
|
* Foreign language
|
|
12
|
|
2
|
131
|
No
|
no
|
|
|
13
|
|
3
|
9
|
No
|
no
|
|
|
14
|
|
4
|
11
|
Yes
|
no
|
* Foreign language
|
|
15
|
|
5
|
5
|
No
|
no
|
|
|
16
|
Openfind
|
1
|
1
|
No
|
no
|
* Foreign language
|
|
17
|
|
2
|
1
|
Yes
|
yes
|
|
|
18
|
|
3
|
2
|
No
|
no
|
* Foreign language
|
|
19
|
|
4
|
5
|
Yes
|
yes
|
|
|
20
|
|
5
|
4298
|
Yes
|
no
|
* Foreign language
|
|
21
|
SinaNet
|
1
|
9
|
Yes
|
no
|
|
|
22
|
|
2
|
6
|
No
|
no
|
|
|
23
|
|
3
|
2
|
Yes
|
no
|
* Foreign language
|
|
24
|
|
4
|
1
|
No
|
no
|
* Foreign language
|
|
25
|
|
5
|
1
|
Yes
|
no
|
|
|
26
|
Todo
|
1
|
31
|
No
|
no
|
|
|
27
|
|
2
|
19
|
No
|
no
|
|
|
28
|
|
3
|
15
|
Yes
|
yes
|
|
|
29
|
|
4
|
6
|
Yes
|
no
|
|
|
30
|
|
5
|
1
|
Yes
|
no
|
|
|
31
|
Yam
|
1
|
128
|
Yes
|
yes
|
|
|
32
|
Yahoo!
|
1
|
169
|
Yes
|
yes
|
|
|
33
|
|
2
|
1
|
Yes
|
no
|
|
|
34
|
|
3
|
1
|
No
|
no
|
|
|
35
|
|
4
|
2
|
Yes
|
no
|
|
|
36
|
|
5
|
160
|
Yes
|
yes
|
|
Figure 7: Identifying relevant Web sites
Based on the data shown in Figure 7, there are 21 relevant Web sites correctly judged by the system. The accuracy in classifying Web sites is 21/36*100=58.33%.
5.2 Finding Clues of Selling Pirated CDs on the Web
In order to identify a site selling pirated CDs on the Web, we start from the following assumption that the CDs are sold at an unreasonably low price. Therefore, our search task is to determine:
To fulfill the above search task we will first construct a database of search concepts. Based on this database we can identify which pages are advertising the sale of CDs. Then, we will further identify the related price made to the public on the Web. Here, the technique of natural language processing is a necessity.
(1) Constructing a Knowledge Base
We select some typical Web pages related to the topic of CD to form the sample space. The pages are selected from five directory-based portal sites for extracting concept terms. Domain experts are asked to judge the representation of these pages concerning our search intention. Irrelevant documents are abandoned and pages are selected anew. Analog to the way of the previous experiment, a representative sample of 122 pages is prepared by human experts, and 879 terms are extracted from them. The most significant concept terms associated with their weights are listed in Figure 8.
| |
Concept
term
|
Frequencies
|
Accumulated occurrences
|
100%
|
99.5%
|
99%
|
97.5%
|
95%
|
90%
|
|
1
|
CD
|
941
|
941
|
10.19
|
10.24
|
10.29
|
10.45
|
10.72
|
11.32
|
|
2
|
Selection
|
536
|
1477
|
15.99
|
16.07
|
16.15
|
16.40
|
16.83
|
17.77
|
|
3
|
Set
|
531
|
2008
|
21.74
|
21.85
|
21.96
|
22.30
|
22.89
|
24.15
|
|
4
|
Piece
|
343
|
2351
|
25.45
|
25.58
|
25.71
|
26.11
|
26.80
|
28.28
|
|
5
|
Selected
Album
|
319
|
2670
|
28.91
|
29.05
|
29.20
|
29.65
|
30.43
|
32.12
|
|
6
|
Chinese
Version
|
300
|
2970
|
32.16
|
32.32
|
32.48
|
32.98
|
33.85
|
35.73
|
|
7
|
Exclusive
Album
|
282
|
3252
|
35.21
|
35.39
|
35.56
|
36.11
|
37.06
|
39.12
|
|
8
|
Disk
|
197
|
3449
|
37.34
|
37.53
|
37.72
|
38.30
|
39.31
|
41.49
|
|
9
|
VCD
|
186
|
3635
|
39.36
|
39.55
|
39.75
|
40.37
|
41.43
|
43.73
|
|
10
|
Album
|
175
|
3810
|
41.25
|
41.46
|
41.67
|
42.31
|
43.42
|
45.83
|
|
Total keywords
|
879
|
833
|
787
|
648
|
417
|
210
|
|
Accumulated occurrences of terms
|
9236
|
9190
|
9144
|
9005
|
8774
|
8313
|
*Percentage is obtained from dividing the accumulated terms occurrences by total term occurrences.
Figure 8: The most frequent terms with their weights at various cut-off values
(2) Determination of Thresholds
From six portal sites, namely, Dreamer , Hinet , Kimo , Openfind , Todo , and Yam , we randomly choose 32 Web sites for providing a total of 3290 pages indexed under CD (Figure 9) as our training set. Let us compare the correctness of our classification with that of these 7 search engines.
| |
Portal Site
|
Web Sites
|
No of pages
|
|
Portal Site
|
Web Sites
|
Page
|
|
1
|
Dreamer
|
1
|
4
|
21
|
|
4
|
1
|
|
2
|
|
2
|
1
|
22
|
|
5
|
3
|
|
3
|
|
3
|
13
|
23
|
Todo
|
1
|
3
|
|
4
|
|
4
|
2
|
24
|
|
2
|
3
|
|
5
|
|
5
|
38
|
25
|
|
3
|
5
|
|
6
|
Hinet
|
1
|
10
|
26
|
|
4
|
16
|
|
7
|
|
2
|
186
|
27
|
|
5
|
1
|
|
8
|
|
3
|
2
|
28
|
Yam
|
1
|
699
|
|
9
|
|
4
|
3
|
29
|
|
2
|
5
|
|
10
|
|
5
|
3
|
30
|
|
3
|
1090
|
|
11
|
Kimo
|
1
|
1
|
31
|
|
4
|
4
|
|
12
|
|
2
|
1
|
32
|
|
5
|
69
|
|
13
|
Openfind
|
1
|
541
|
|
|
|
|
|
14
|
|
2
|
13
|
|
|
|
|
|
15
|
|
3
|
1
|
|
|
|
|
|
16
|
|
4
|
1
|
|
|
|
|
|
17
|
|
5
|
1
|
|
|
|
|
|
18
|
SinaNet
|
1
|
534
|
|
|
|
|
|
19
|
|
2
|
7
|
|
|
|
|
|
20
|
|
3
|
29
|
Total
|
|
|
3290
|
Figure 9: Selected pages indexed under CD in portal sites and Web sites
These 3290 pages, which are considered as being relevant for CD by other search engines, are the input to our system. The system output (Figure 10) gives us a hint to determine the optimal threshold based on recall and precision. Figure 10 also shows the difference between the results provided by our system and human experts. 2907 of the 3290 pages are verified as relevant for the search intention by human experts.
|
Accumulated weight of
a page (¥)
|
Pages
selected by
our system
|
Correct pages
judged by
domain experts
|
Pages with
weight ¥ the weight
indicated in column 1
|
Precision
|
Recall
|
|
0.005
|
3273
|
2907
|
2907
|
88.82
|
100.00
|
|
0.01
|
3053
|
2794
|
2907
|
91.52
|
96.11
|
|
0.02
|
3051
|
2792
|
2907
|
91.51
|
96.04
|
|
0.03
|
3044
|
2788
|
2907
|
91.59
|
95.91
|
|
0.05
|
3041
|
2787
|
2907
|
91.65
|
95.87
|
|
0.10
|
3036
|
2784
|
2907
|
91.70
|
95.77
|
|
0.11
|
3034
|
2782
|
2907
|
91.69
|
95.70
|
|
0.12
|
3030
|
2779
|
2907
|
91.72
|
95.60
|
|
0.13
|
3020
|
2769
|
2907
|
91.69
|
95.25
|
|
0.14
|
3018
|
2768
|
2907
|
91.72
|
95.22
|
|
ò
ò
ò
ò
|
ò
ò
ò
ò
|
ò
ò
ò
ò
|
ò
ò
ò
ò
|
ò
ò
ò
ò
|
ò
ò
ò
ò
|
|
13.79
|
1814
|
1704
|
2907
|
93.94
|
58.62
|
|
13.80
|
1768
|
1700
|
2907
|
96.15
|
58.48
|
|
13.83
|
1767
|
1699
|
2907
|
96.15
|
58.45
|
|
13.90
|
1766
|
1698
|
2907
|
96.15
|
58.41
|
|
13.92
|
1765
|
1697
|
2907
|
96.15
|
58.38
|
|
14.02
|
1763
|
1695
|
2907
|
96.14
|
58.31
|
|
ò
ò
|
ò
ò
|
ò
ò
|
ò
ò
|
ò
ò
|
ò
ò
|
|
3396.78
|
5
|
5
|
2907
|
100.00
|
0.17
|
|
3545.12
|
4
|
4
|
2907
|
100.00
|
0.14
|
|
4128.15
|
3
|
3
|
2907
|
100.00
|
0.10
|
|
4411.46
|
2
|
2
|
2907
|
100.00
|
0.07
|
|
6052.15
|
1
|
1
|
2907
|
100.00
|
0.03
|
Figure 10: Determination of threshold based on recall and precision
Experiments are also made at different cut-off values ( Gordon and Pathak 1999 ) upon accumulated term occurrences. Corresponding thresholds are listed in Figure 11, where we can ascertain that the choice of support value at 13.8 for 99.5% of the total term occurrences is adequate, and we obtain 96.15% retrieval precision and 58.48% recall. It shows the superiority of the e-Detective system in precision in comparison with the classification precision, 89%, of other search engines.
|
Percentage of accumulated term occurrences
|
Threshold for
support value
|
Precision (%)
|
Recall (%)
|
|
99.5%
|
13.80
|
96.15
|
58.48
|
|
99%
|
14.34
|
95.37
|
58.43
|
|
97.5%
|
13.76
|
96.03
|
58.47
|
|
95%
|
13.92
|
95.87
|
58.34
|
|
90%
|
14.61
|
96.11
|
58.13
|
Figure 11: Thresholds at various cut-off values of percentage of accumulated term occurrences
5.3 Summary of the Experiments
The findings in the experiments are summarized as follows:
1) We use the databases of concepts as a basis for searching data from the Web; however, not all concepts are to be used. While we use 99.5% of the most significant terms to search CDs and attain optimal retrieval relevance, we use 97.5% of the most significant terms in searching pornographic information;
2) The threshold for searching pornographic information is 3.75 in contrast to the threshold of 13.8 for searching CD-related information. The reason for this difference is that there are more narrative descriptions in CD-pages than the overwhelming pictures in pornographic pages;
3) 100% accuracy in classifying CD Web sites is much better than 58.33% accuracy in classifying pornographic pages. The reason lies in the amount of narrative information contained in the pages;
4) Searching crime information is beyond syntactical comparison; semantic analysis should follow in order to extract interesting information.
6. Conclusion and Discussion
To search crime information is not an easy task. In this paper we give the idea of constructing a proprietary search engine for law enforcement agencies, called the e-Detective , which differs from a common search engine in many aspects: It can process Web pages both syntactically and semantically. It may work assiduously in background and report the search result periodically. It provides the user with a well-ranked list of relevant pages for easy reference, and it organises interesting Web sites such that it knows where to acquire information the user wanted.
The first set of statistics of system evaluation shows that the precision is high in the notion of information retrieval. Thus, it is convinced to be capable of carrying out retrieval tasks to find information for supporting crime investigation. Even though the recall remains humble commensurate to precision, research in this direction deserves our dedication in the future. Another research direction is the application of image processing technique in crime information search.
References
Bruza P D and van der Weide T P (1991) 'The Modelling and Retrieval of Documents Using Index Expressions', ACM SIGIR FORUM 25(2), 91-102.
Baeza-Yates R A (1998) 'Searching the World Wide Web: Challenges and Partial Solutions', Proceedings of Annual Meeting of Pacific Neighborhood Consortium, (May 15-18), Taipei, 153-166.
Chen P S (1994) 'On Inference Rules of Logic-Based Information Retrieval Systems', Information Processing & Management, Vol. 30, No.1, 43-59.
Chen P S and Hennicker R and Jarke M (1995) 'On the Retrieval of Formal Specifications for Reuse', Journal of the Chinese Institute of Engineers.
Chen P S (1998) Collection and Investigation of Illegal Information on Networks, Technical Report (in Chinese), (Taoyuan: Central Police University).
Filman R and Pena-Mora F (1998) 'Seek, And Ye Shall Find', IEEE, Internet Computing, (July/August ), 78-83.
Gordon M and Pathak P (1999) 'Finding Information on the World Wide Web: the retrieval effectiveness of Search Engines', Information Processing & Management 35, 141-180.
Konopnicki D and Shmueli O (1995) 'W3QS: A Query System for the World-Wide Web', Proceedings of the 21st International Conference on Very Large Data Bases, 54-65.
Salton G and McGill M J (1983) Introduction to Modern Information Retrieval, (New York: McGraw-Hill).
Tesniere L (1959) Elemente de Syntaxe Structurale, (Paris: Klincksieck)
Hyperlinks
< http://www.altavista.com >
< http://www.yahoo.com >
< http://www.openfind.com.tw >
< http://www.dreamer.com.tw/>
< http://www.hinet.net/>
< http://www.kimo.com.tw/>
< http://www.todo.com.tw/>
< http://www.yam.com.tw/>
|